

Better and safer drivers. More personalized user experiences, be it your music, your insurance, your vitality program, your social network. Sentiance puts the consumer at the center and improves their life through context aware services. We work with clients who care deeply about their consumers and our process is never transactional. Our service is differentiated by strong relationships and open communication. This is often most visible when our business development and client services teams engage with our customers, but behind the scenes is a battalion of technical talent committed to delivering client value.
Our technical teams work cross-functionally to drive results in what we call core teams. These teams share similar principles to squads and agile methods where ownership, agility and autonomy are conditions for success. And like any organisation, we evolve as our needs change.
Where previous articles have already looked under the technical hood at Sentiance, in this post we offer a behind the scenes look into the formal technical roles and informal personalities who make up the Sentiance technical team. We begin with a few foundational basics, our platform and software engineering principles.
Our platform
The Sentiance Platform maintained by the Software Development Group at Sentiance is a data processing platform. It starts with data collection through a Mobile SDK to capture sensor data in an automated way. This raw data is ingested into a fully cloud-native processing environment on Amazon Web Services, using Kafka as a streaming communication layer. Several reactive, container-based and batch-oriented workloads transform this raw data into higher-level, actionable insights. This magic happens through a mix of AI technologies, from standard machine learning models to more state of the art deep learning networks. The insights extracted by our intelligent layers are then made available to Customers through (1) a pull-based GraphQL API, (2) a push-based Firehose through Webhooks and (3) file-based offloads.
Software engineering is core
When developing a new software component for the Sentiance Platform (or when updating an existing component), the team aims to maintain the availability of that component. Availability is used here in the sense that a component that is highly available provides the confidence that it is serving its intended purpose.
Therefore, a number of engineering principles are taken into account:
- Stability & reliability: Having a standardized development cycle and stable deployment pipeline.
- Security & privacy: Using secure coding practices and infrastructure configuration to keep the platform safe from external and internal attacks and ensure that private user data remains private.
- Scalability & performance: Making efficient use of resources, knowing how the software operates under load and understanding the scaling options and limits.
- Fault Tolerance: Capturing potential failure scenarios, understanding their risk to the business and being resilient when failure happens.
- Observability: Having relevant logging, proper monitoring and alerts to detect issues and being able to report on how the component is operating.
- Documentation: Documenting the design and operations of the component with an eye for knowledge transfer and on-boarding new developers.
The overall goal is to ensure production-ready software development and deployment.
As the implementation of a machine learning pipeline is mostly about software engineering, most of those principles are also applicable for machine learning pipeline development. Additional principles that are not directly relevant for standard software engineering are added for machine learning:
- Data characterization: Using an offline framework to collect, understand, track, and describe labeled datasets as well as input data and features.
- Model development: Proposing a standard way to research and implement machine learning pipelines including metric definition, experiment tracking, checking accuracy on different data slices and so on.
- Machine learning infrastructure: Providing reproducible and automated pipelines. Implement machine learning specific integration and integration testing.
- Machine learning monitoring: Providing online tools to track potential changes in input and output data statistics as well as model staleness and online accuracy.
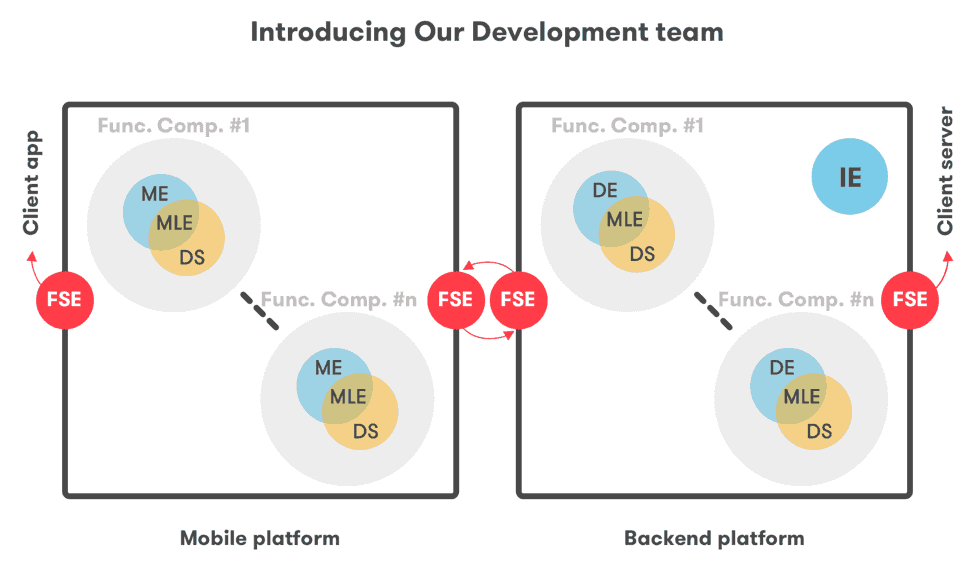
FSE: Full Stack Engineer. ME: Mobile Engineer. MLE: Machine Learning Engineer. DS: Data Scientist. DE: Data Engineer. IE: Infrastructure Engineer

Infrastructure Engineer
When asked, our SRE team liken their role to the valiant efforts of Star Trek’s Scotty, levering at a mad pace to deliver warp speed to the USS enterprise. Alone in the bowels of the spaceship, stoic in knowing he’ll never be asked how or why, but only for more and now, Scotty gives heart and power for the behemoth to go light speed.
Infrastructure Engineers (IE) primarily provision and maintain scalable cloud infrastructure. They apply software engineering principles in doing so, by using Infrastructure-as-code (IaC) abstraction frameworks and automation. Change management is really important in deploying stable processing environments. Having all infrastructure changes in source control ensures there is traceability and reproducibility. We need to be able to deploy the exact same environment multiple times, in order to either distribute our multi-tenant processing environments globally, or to be able to serve single tenancy.
IEs also need to observe what’s going on. Not only to make sure everything is working as expected, but also to avoid bottlenecks and to make sure not to overprovision (and keep costs down).
Typically, an infrastructure engineer joins the Site Reliability Engineering (SRE) team within Sentiance.
At Sentiance, we use the Hashicorp ecosystem: Packer and Terraform for provisioning. Consul and Vault for Service Discovery and (secured) K/V store and secrets engine. Nomad as scheduler for running docker-based microservices. We use Ansible for config management. We deploy mainly on AWS.
Fun fact: each of our processing environments is named after a certain science fiction spaceship.

Data Engineer
The Data Engineering corps first called themselves the undefeatable Super Mario, an unsung ordinary hard working hero, a ‘go to’ guy that can thrive in any platform game, jumping from one pipeline to another, often underground. But perhaps the best parallel comes from a galaxy far far away with the grumpy but loyal Han Solo and Chewbacca. These anti-heroes work to transport cargo from A to B by whatever means necessary, resurrecting the Millennium Falcon, navigating asteroid riddled highways, and at times even facing off with the forces of darkness.
Data Engineers (DE) design, develop and maintain the data processing pipelines of the Sentiance Platform. They have a software engineering background which has been augmented with skills in data modeling, distributed systems and cloud infrastructure.
At Sentiance the skills of a data engineer need to cover ’big data’ in all dimensions: payloads can be big in size, in numbers and in frequency. In addition, the many different data processing steps can vary from straightforward ETL actions, to executing CPU- or memory-intensive algorithms developed by our data science team. The backend platform is where the magic happens and low-level data gets transformed into rich Sentiance insights. This engine is under continuous development with code updates or new functionality so a data engineer’s mindset must combine agility, resiliency and scalability.
Data engineers speak at least Java and Python, know how to ship in Docker containers, are experienced in NoSQL/SQL databases and adore frameworks like Kafka and Spark.

Mobile Engineer
The Guardians of the Galaxy are a band of intergalactic outlaws, who teamed together to protect the galaxy from planetary threats.
"A bit of an outsider from the Sentiance Platform, a bit apart from DS, DE, and SRE. Our languages are even a bit different… Is this not exactly us? "
- a mobile engineer
Mobile engineers are software engineers developing on the iOS and/or Android platforms. The mission of the mobile engineer is, simply put, to collect high-quality data with minimal use of CPU cycles, memory, and battery while respecting OS permission governance and user privacy. Therefore, it’s not classic app development, but rather optimizing background processing by leveraging low-level APIs. Mobile engineers are expected to have a solid understanding of how the OS governs the background processes, optimizing sensor reading, network I/O, and have a data-driven mindset.
We expect junior mobile engineers to have a solid understanding of sensor APIs and application life cycle. Of course, the foundation has to come from having strong computer science fundamentals and understanding test-driven development. With experience, the mobile developer goes beyond this and is expected to handle client interactions and projects that affect various parts of our product and data ingestion pipeline. Our mobile engineers must be versatile and have a high-level understanding of the backend so they are able to work with engineers with different functions.
Fine-grain understanding of the trade-offs between data collection rate and hardware usage differentiate the senior mobile engineers, who are able to dive into OS source code to see what is going on under the hood. Senior mobile engineers are directly accountable for the quality of the SDK, therefore they must be well experienced in designing public and private APIs, making data-driven decisions, know the OS’ APIs inside out, and able to architect scalable code.

Data Scientist
We have a lot of variance in the data science team: the Mad Scientist, Dora the Explorer, Alf, Alice in Wonderland eager to scramble down the rabbit hole. ‘Spock obviously,’ says one. ‘Captain Kirk,’ says another. Gimli the dwarf always searching for gold. Neo in the Matrix. Iron man, thinking he knows everything (okay, that might’ve come from a data engineer). Evidence of the multi-dimensional complexity of the Data Scientist, the one who puts his finger in the electrical socket just to see what happens, who carries her tools in her trusty backpack to explore, count and measure, who is always ready to test or contemplate a hypothesis in pursuit of insight.
Following client and road map requirements, data scientists design functional data processing pipelines or improve existing ones following the typical machine learning process: data analysis, cleanning, feature engineering, model training and validation. Techniques range from standard machine learning algorithms to more advanced deep learning.
Non-machine learning pipelines such as sensor signal processing, rule based systems, or statistical analysis are also on our production platform and owned by data scientists.
Data scientists also perform off-line analysis of platform data to help clients during proof of concepts or to assign the quality and sanity of the data flow.
Data scientists follow software engineering best practices when coding. Key differentiators for determining level include the actual experience with machine learning and scientific methodology, mastery of python and software engineering, and fields of interests for Sentiance.
Specialized fields of interest for MLE and DS include:
- Signal processing
- Geo-spatial data processing
- Natural language processing
- Social network analysis
- Recommender system
- Time series analysis
- (Adaptive) experimentation techniques
- Causal inference
Machine Learning Engineer
At first, we looked for a persona that unites ‘two warring factions’, until we realized our DS and DE brethren are not at war but often just in need of a bit of translation. So we shifted from thinking of our MLE as ‘the one ring to rule them all’ and focused on their universal translation capability, and tooling and ambidextrous skills. Options included Doctor Who and his TARDIS, pick-your-fave shapeshifter, but with the machine reference in mind, we go with those talented and critical timeless droids C3PO and R2D2.
MLEs assist data scientists in creating production ready pipelines. Besides yielding high functional accuracy, our machine learning pipelines must be scalable and optimized with respect to CPU and memory footprint.
MLEs also assist data engineers and mobile engineers in integrating the machine learning pipelines on our backend and mobile production platforms in an efficient and scalable way.
As shown in the figure, MLEs bridge the gaps between data scientists and engineers. They need to speak the language of both. Even if they are part of the data science team they follow all engineering assemblies and implement the production readiness guidelines. They bring and consolidate new engineering knowledge into the data science team.
MLEs also create efficient tooling used for machine learning research, development, deployment, and monitoring e.g. experiment tracking, training pipeline automation, fast model deployment, or online monitoring of the different machine learning pipelines.
What differentiates the Junior from the Senior relates to their level of experienced software engineering skills, knowledge of machine learning, and as with our Data Scientist, field of interest for Sentiance.

Full-Stack Engineer
To say the Full Stack Engineer is a ninja is too simple, so we prefer the stealth and style of the elves. Nimble all-round warriors, versatile in languages, ours are elite in their broad range of skills, often working under the radar with an eye for elegant code and design.
Full-Stack Engineers (FSE) focus on APIs and frontends for mobile apps, custom web-based dashboards and internal tooling.
Just like Infrastructure Engineers, Data Engineers and Machine Learning Engineers, a DevOps mentality is cultivated with FullStack Engineers. They are able to not only develop their components, but also create the build pipelines in our CI/CD system, execute deployments to our production environments and monitor them for proper operations.
APIs are built using Node.JS and can be both RESTful and GraphQL-based. Strong automated testing principles are upheld to maintain velocity in rolling out new features and bugfixes. Mobile apps are developed using React-Native to cover iOS and Android in one go. Web dashboards are implemented in React and include both customer-facing dashboards that allow tracking of ongoing PoCs as well as internal dashboards to assess data quality in various parts of the processing flow.
They also regularly integrate with other systems for data access and storage like PostgreSQL, Elasticsearch, Kafka and more.

Our Fellowship
Of course, our technical team is not complete without a robust delivery project management team and a crew of innovative designers who come replete with their own unique super powers. And we have not touched upon the mystical powers of our behavioral change team. Still, we hope this gives you a sense of who we are, what we do and that we have fun doing it.
Feel like the fate of humankind is in your hands? Or at least that you want to have an impact towards our betterment through the power of ethical AI and machine learning? Then we invite you to check out our jobs and begin your own journey quest towards Motion, Moments and Magic at Sentiance.
But don’t take our word for it. In the wise words of the great Master Yoda:
“Always in motion the future is.”





