

How we deploy and scale
A VIP tour behind the curtains of our cloud-native scalable and automated infrastructure
Introduction
Billions of location points, accelerometer, gyroscope and other sensor data flow from mobile devices of people all over the world to Sentiance’s platform on a daily basis. These demand real-time analysis and responses, so as to allow us to observe and predict users’ behaviors, and to coach and retain them accordingly. But all the awesome machine learning and data science applications our team has put together - and continues to assemble- wouldn’t be able to run if not supported by reliable and auto-scaling infrastructure management. Therefore, in this post, we will cover some of the tools and automation we use to manage the Sentiance Platform.
Deployment workflow
As an exercise, let’s assume a Data Engineer is working on a new service and needs a place to deploy it. Below are the five steps of an infrastructure deployment at Sentiance along with the tools and technologies involved in each step.

Imagine that you received a brand new computer at work. Before you can actually start doing anything productive with it, you will spend about an afternoon just installing the tools you need: your favorite browser, text editor, antivirus, configuring email accounts and so on, right? Now, imagine that your computer is replaced every month. Every week. Every day. Every hour. Sometimes every minute! There’s no way you want to keep wasting time on these pre-config steps. So, since you cannot avoid switching computers, wouldn’t it be a lifesaver to have all those tools ready to go on your new computer? That’s what this step is about: Preparing, in an automated way, a customized Operating System pre-configured for any service every time a new server is created.
The process begins on our Continuous Integration server, Jenkins, where the Engineer will start a build job. This job contains instructions for Packer, software specialized in preparing customized operating system images. Packer will create a temporary machine with the base OS we want, e.g. Ubuntu, and execute a list of actions on it. These actions are declared in an Ansible playbook, a reliable configuration management tool. Once all tasks in the playbook have finished executing, Packer will save the state of the OS as an AMI (Amazon Machine Image) and discard the machine. Now we can create as many new servers as we want using this AMI and be sure that all of them have the same configuration!
At this point, we are ready to provision the infrastructure. Using Terraform, a tool to implement the Infrastructure-as-Code pattern, we create a spot fleet request and configure it to create or delete servers according to the load being processed by the service in realtime. Thanks to having 100% of the infrastructure declared as code, it only takes a few minutes and one pull request for this to happen.
Spot fleet instances are a kind of virtual auction where you bid to get servers. Although much cheaper than regular on-demand instances (up to 90% in some cases), they are susceptible to termination if you get outbid or if Amazon needs them back to assist someone requesting on-demand servers. To mitigate this risk we diversify our spot requests with at least two instance types from different families, because chances are lower that two family types will be fully in use.
The screenshot below will help you understand what kind of variables we set to create the spot fleet request and configure its auto-scaling. For instance, the service is meant to have an average CPU utilization of 75% and AWS is allowed to scale the number of EC2 instances it runs on automatically between 1 and 20 to keep the desired utilization rate.
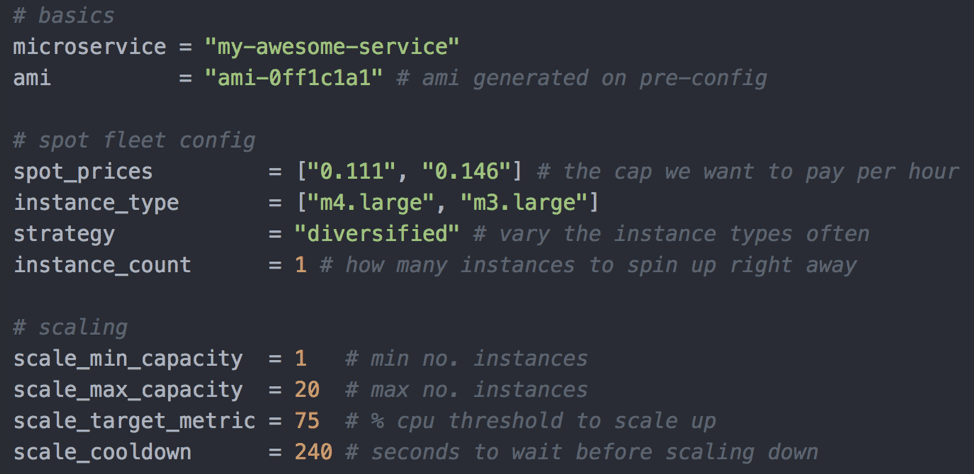
The Site Reliability Engineering team will ensure that the Terraform code is applied and after it's live, the instance(s) will automatically ask for any necessary post-config actions by calling AWX, which provides an API and UI to help running Ansible playbooks. The most important action in this step is deploying and configuring monitoring support on the instance, so it can send metrics and have its performance and usage monitored right away. AWX will also periodically run playbooks on all servers to make sure no unauthorized changes to the default configuration have been made.

Cool, in almost no time the Engineer has servers ready for the service to be started on. Now, all there is left to do is to ask Nomad to deploy and start it. This is done in the allocation step, exactly because Nomad can be compared to the world’s best Tetris player, allocating pieces around where they fit best. Once Nomad receives the job definition, a structured JSON file, it determines how much CPU and Memory the job needs and looks for a server that fits those requirements. After selecting where to deploy the service, Nomad downloads the Docker image from our private registry, starts the container and the service is running!
Nomad will also perform zero-downtime updates if a new version of the job is released, and keeps track of both service and container’s health, to ensure it’s always running.
Last but not least, we have the Discovery & Secrets step where Consul provides service discovery and DNS naming and Vault provides secrets management. Consul is a lightweight service discovery and key-value store tool used to group all instances of a service under a common DNS name and to guarantee the unhealthy ones don’t receive requests by actively performing health checks and updating its DNS records.
Vault allows services to securely fetch API keys, passwords and all kinds of sensitive information without it ever being committed to a repository or just lay as plain text in a configuration file. And both Consul and Vault integrate easily with Nomad, saving a lot of SRE time as Nomad will engage with these services seamlessly according to what was configured in the job definition file from the previous step.

Nomad vs Kubernetes
If you are familiar with cloud-native environments and microservice orchestration you probably noticed that Kubernetes is nowhere to be found in our tooling ecosystem and it might seem strange given the fact that it has apparently become the default container orchestrator in modern architectures. Well, it’s not that we don’t like it, but it’s just too much for our use case.
K8s can be represented as a well-equipped service truck while Nomad is more like a fast and agile delivery motorcycle, but one which – surprisingly perhaps – can handle a similar workload. So we happily settle for the motorcycle, as Nomad doesn’t add any operational overhead and has a very concise scope and straightforward usability that outsmarted K8s in our use case. Therefore, why complicate it? If you have small loosely-coupled services you probably don’t need a K8s cluster and all of its complexity and time-consuming maintenance.
Conclusion
When a platform transitions from hundreds of users to hundreds of thousands, processing millions of requests daily, time is key and wasting it with manual interventions and duplicate work can slow the entire spaceship down. That’s why we are proud to have such a workflow today. But being satisfied with each new step doesn’t equal leaning back. It is necessary to iterate constantly, seek improvement, agility, and effectiveness, striving to make it better every day. So we don’t just keep the spaceship on the air, but equip it for even greater journeys.





